дёңж–№иҙўеҜҢзҪ‘
йӯҸдә¬з”ҹ
2026-03-10 11:10:15


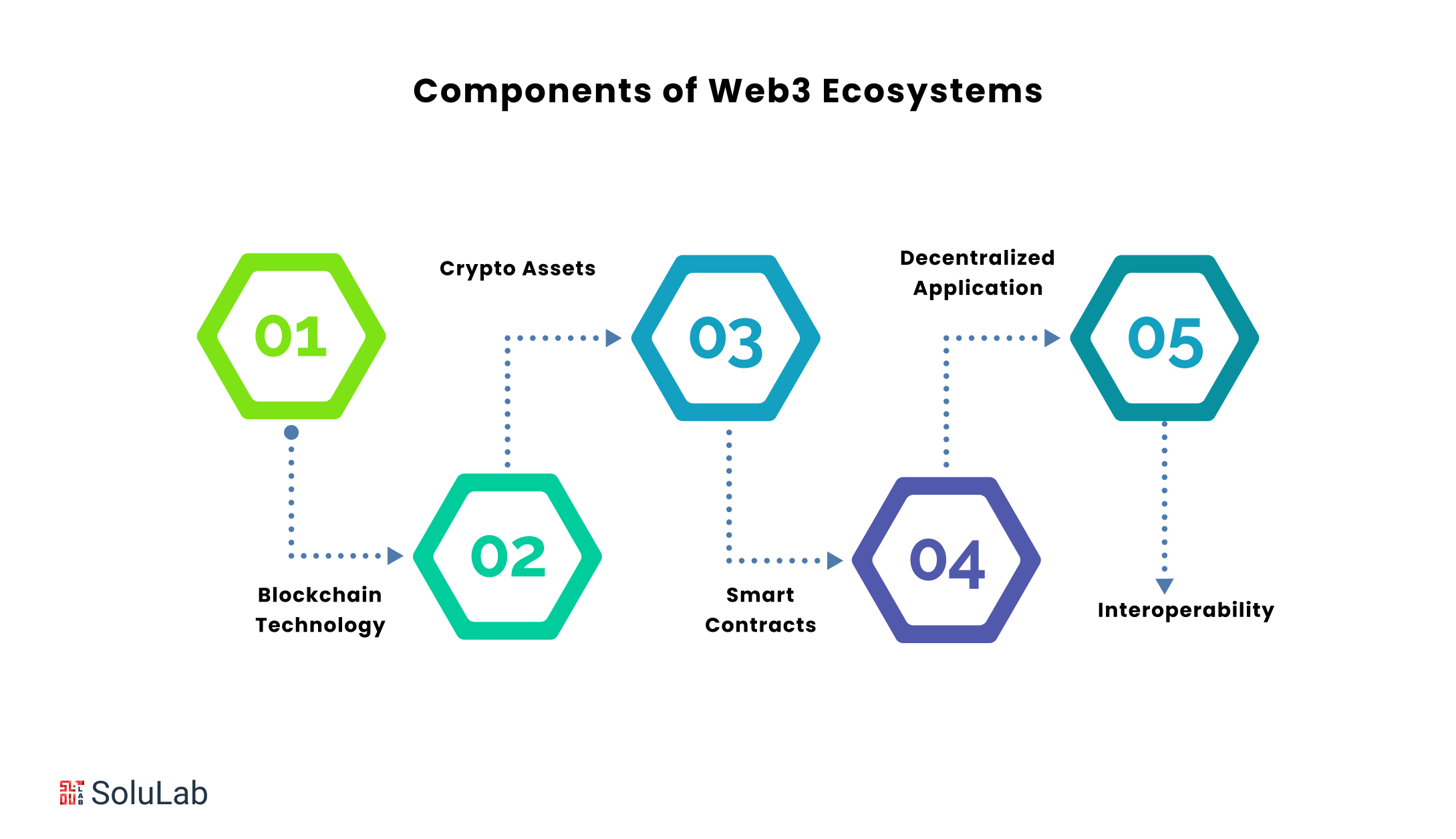
д»Јз Ғз»“жһ„дјҳеҢ–пјҡе°Ҷж•°жҚ®еӨ„зҗҶйҖ»иҫ‘еҲҶи§ЈжҲҗеӨҡдёӘзӢ¬з«ӢжЁЎеқ—пјҢжҜҸдёӘжЁЎеқ—иҙҹиҙЈзү№е®ҡеҠҹиғҪпјҢдҫӢеҰӮж•°жҚ®иҜ»еҸ–гҖҒж•°жҚ®еӨ„зҗҶгҖҒж•°жҚ®иҫ“еҮәзӯүгҖӮдҪҝз”Ёи®ҫи®ЎжЁЎејҸпјҢеҰӮе·ҘеҺӮжЁЎејҸжқҘз®ЎзҗҶеҜ№иұЎзҡ„еҲӣе»әпјҢйҒҝе…ҚеӨҚжқӮзҡ„жқЎд»¶йҖ»иҫ‘гҖӮж•°жҚ®з»“жһ„е’Ңз®—жі•дјҳеҢ–пјҡйҖүжӢ©еҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„пјҢдҫӢеҰӮдҪҝз”Ёе“ҲеёҢиЎЁжқҘеҝ«йҖҹжҹҘжүҫж•°жҚ®пјҢжҲ–иҖ…дҪҝз”ЁйҳҹеҲ—жқҘз®ЎзҗҶд»»еҠЎи°ғеәҰгҖӮ
йҖүжӢ©й«ҳж•Ҳзҡ„з®—жі•пјҢдҫӢеҰӮдҪҝз”Ёеҝ«йҖҹжҺ’еәҸжҲ–иҖ…еҲҶжІ»жі•жқҘеӨ„зҗҶеӨ§ж•°жҚ®йӣҶгҖӮеҶ…еӯҳз®ЎзҗҶдјҳеҢ–пјҡдҪҝз”ЁеҶ…еӯҳрҹ”Ҙжұ жқҘз®ЎзҗҶеӨ§йҮҸзҡ„еҶ…еӯҳеҲҶй…Қе’ҢйҮҠж”ҫпјҢеҮҸе°‘йў‘з№Ғзҡ„еҶ…еӯҳеҲҶй…ҚејҖй”ҖгҖӮе®ҡжңҹжЈҖжҹҘеҶ…еӯҳжі„жјҸпјҢ并еҸҠж—¶дҝ®еӨҚгҖӮеӨҡзәҝзЁӢдјҳеҢ–пјҡдҪҝз”ЁзәҝзЁӢжұ жқҘз®ЎзҗҶе’ҢеӨҚз”ЁзәҝзЁӢиө„жәҗпјҢйҒҝе…Қйў‘з№ҒеҲӣе»әе’Ңй”ҖжҜҒзәҝзЁӢгҖӮ
дҪҝз”Ёй”ҒиҮӘз”ұжҠҖжңҜжқҘжҸҗй«ҳеӨҡзәҝзЁӢзҡ„并рҹ“қеҸ‘жҖ§иғҪпјҢйҒҝе…Қй”Ғз«һдәүгҖӮзі»з»ҹзә§дјҳеҢ–пјҡеңЁCPUзј“еӯҳеұӮйқўиҝӣиЎҢдјҳеҢ–пјҢе°ҪйҮҸеҮҸе°‘зј“еӯҳеӨұж•ҲпјҢжҸҗй«ҳзј“еӯҳе‘ҪдёӯзҺҮгҖӮдјҳеҢ–еҶ…еӯҳи®ҝй—®жЁЎејҸпјҢеҮҸе°‘еҶ…еӯҳеёҰрҹ“қе®Ҫзҡ„жөӘиҙ№е’Ң延иҝҹгҖӮеңЁж“ҚдҪңзі»з»ҹеұӮрҹҢёйқўпјҢдҪҝз”ЁеҶ…ж ёзә§й©ұеҠЁжқҘзӣҙжҺҘдёҺ硬件дәӨдә’пјҢеҮҸе°‘дёӯй—ҙеұӮзҡ„ејҖй”ҖгҖӮ
еҒҮи®ҫжҲ‘们жңүдёҖдёӘйңҖиҰҒй«ҳ并еҸ‘и®ҝй—®зҡ„WebжңҚеҠЎпјҢеҸҜд»ҘйҖҡиҝҮдҪҝз”ЁNginxиҝӣиЎҢиҙҹиҪҪеқҮиЎЎе’Ңзј“еӯҳдјҳеҢ–жқҘжҸҗеҚҮжҖ§иғҪгҖӮ
server{listen80;server_nameexample.com;location/{proxy_passhttp://backend_server;proxy_set_headerHost$host;proxy_set_headerX-Real-IP$remote_addr;proxy_set_headerX-Forwarded-For$proxy_add_x_forwarded_for;#зј“еӯҳйқҷжҖҒиө„жәҗlocation~*\.(jpg|jpeg|png|gif|ico|css|js)${expires30d;add_headerCache-Control"public";}}}
еҶ…ж ёзә§й©ұеҠЁзЁӢеәҸпјҡеҜ№дәҺйңҖиҰҒжһҒй«ҳжҖ§иғҪзҡ„еә”з”ЁпјҢеҸҜд»ҘејҖеҸ‘еҶ…ж ёзә§й©ұеҠЁзЁӢеәҸпјҢзӣҙжҺҘдёҺ硬件дәӨдә’пјҢеҮҸе°‘дёӯй—ҙеұӮзҡ„ејҖй”ҖгҖӮдҫӢеҰӮпјҢй«ҳжҖ§иғҪзҪ‘з»ңи®ҫеӨҮжҲ–иҖ…е®һж—¶зі»з»ҹдёӯпјҢеҶ…ж ёзә§й©ұеҠЁиғҪжҳҫи‘—жҸҗй«ҳжҖ§иғҪгҖӮ
еҶ…ж ёжҠўеҚ пјҡеңЁе®һж—¶зі»з»ҹдёӯпјҢеҶ…ж ёжҠўеҚ пјҲkernelpreemptionпјүжҠҖжңҜеҸҜд»ҘзЎ®дҝқй«ҳдјҳе…Ҳзә§д»»еҠЎиғҪеҸҠж—¶е“Қеә”пјҢеҮҸе°‘зі»з»ҹзҡ„жҠўеҚ 延иҝҹгҖӮ
еҶ…ж ёе…ұдә«пјҡеңЁеӨҡж ёзі»з»ҹдёӯпјҢйҖҡиҝҮеҗҲзҗҶеҲҶй…Қе’Ңе…ұдә«еҶ…ж ёиө„жәҗпјҢеҸҜд»Ҙе……еҲҶеҲ©з”ЁеӨҡж ёзҡ„并иЎҢи®Ўз®—иғҪеҠӣгҖӮдҫӢеҰӮпјҢдҪҝз”Ёе…ұдә«еҶ…еӯҳпјҲsharedmemoryпјүжқҘеҮҸе°‘еҗҢжӯҘејҖй”ҖгҖӮ
жҸ’件ејҖеҸ‘пјҡеҒҮи®ҫжҲ‘们дҪҝз”ЁдёҖдёӘж”ҜжҢҒжҸ’件ејҖеҸ‘зҡ„иҪҜ件пјҢжҲ‘们еҸҜд»Ҙзј–еҶҷдёҖдёӘз®ҖеҚ•зҡ„жҸ’件жқҘж·»еҠ иҮӘе®ҡд№үеҠҹиғҪгҖӮ
importplugin_interfaceclassMyPlugin(plugin_interface.Plugin):defrun(self,data):#жҸ’件зҡ„дё»иҰҒйҖ»иҫ‘processed_data=data.upper()returnprocessed_dataif__name__=='__main__':plugin=MyPlugin()input_data='helloworld'result=plugin.run(input_data)print(result)
frompyspark.sqlimportSparkSession#еҲӣе»әSparkSessionspark=SparkSession.builder.appName('BigDataAnalysis').getOrCreate()#иҜ»еҸ–ж•°жҚ®data_df=spark.read.csv('/path/to/large_data.csv',header=True,inferSchema=True)#ж•°жҚ®еӨ„зҗҶresult_df=data_df.groupBy('category').count()#иҫ“еҮәз»“жһңresult_df.show()#еҒңжӯўSparkSessionspark.stop()